Extract Product, Price, Rating, URL from Amazon to excel
In this article, we are performing data scraping of product name, price, rating, url from Amazon to csv or excel using Robocorp.
To achieve this task we are using python as well.
Task Details:
- Open Amazon.in browser
- Search for mobiles
- Extract the required details from amazon
- Store those details in excel or csv
You can check the below mentioned video for reference:
The code that is shown in the video is given below:
tasks.robot
*** Settings ***
Documentation Template robot main suite.
Library RPA.Browser.Selenium
Library RPA.Tables
Library DataScraper
Library Collections
*** Variables ***
@{headers}= Name Price Rating URL
*** keywords ***
Opening Amazon browser
Open Available Browser https://www.amazon.in/s?k=mobiles&crid=3TO1931SQACQ8&sprefix=mobile%2Caps%2C367&ref=nb_sb_noss_1 maximized=True alias=FirstBrowser
Sleep 2s
DataScraping Results
${data}= Get WebElements //div[contains(@class, "s-result-item s-asin")]
${amazonData} Create List
FOR ${element} IN @{data}
Capture Element Screenshot ${element}
${text}= Get result text ${element}
${price}= Get Result Price ${element}
${url}= Get result url ${element}
${rating}= Get Result rating ${element}
${amazonList}= Create List ${text} ${price} ${rating} ${url}
Append To List ${amazonData} ${amazonList}
END
[Return] ${amazonData}
*** Tasks ***
Datascraping Demo
Opening Amazon browser
${amazonData}= DataScraping Results
${Amazontable}= Create Table ${amazonData} columns=@{headers}
Write Table To Csv ${Amazontable} ${CURDIR}${/}output${/}AmazonData.csv
Datascraper.py
def get_result_text(result) -> str:
try:
return result.find_element_by_tag_name("h2").text
except:
return ""
def get_result_url(result) -> str:
link = result.find_element_by_tag_name("a")
return link.get_attribute("href")
def get_result_price(result) -> str:
try:
return result.find_element_by_class_name("a-price-whole").text
except:
return ""
def get_result_rating(result) -> str:
try:
rating = result.find_element_by_xpath('.//div[@class="a-row a-size-small"]/span')
return rating.get_attribute("aria-label")
except:
return ""
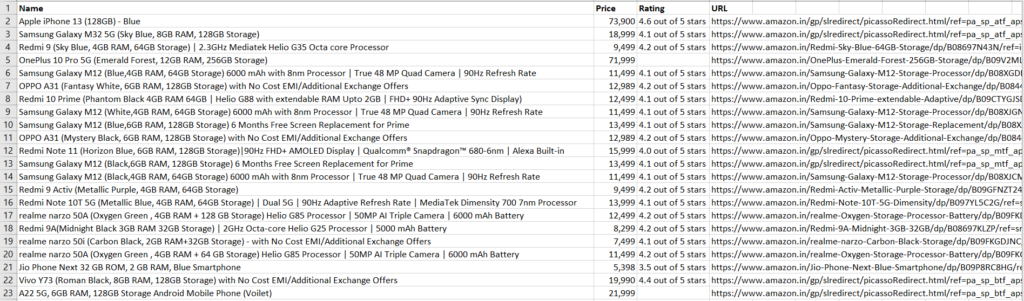
The output of the above code looks like this:
Happy Learning!
ADITYA
0